



Vigil #2 - Camera Feed Extractor
Developing the first piece of Vigil, the real-time traffic accident detection system


Do things that don’t scale
This phrase and essay by Paul Graham have become so popular, it is almost a cliché nowadays. But not only is it a great approach to early stage startups, it is also very applicable to software development. I am a firm believer in spending time in developing proofs of concept (POCs) before starting a full bore implementation of the designed system. A good POC that tries to cover much of the end-to-end data flow in a scaled down way is great for proving or disproving assumptions made during the design phase, as well as uncovering some of those pesky unknown unknowns!
If you’ve been with us since the start, you know that I am using this newsletter to document my journey as I attempt to build machine learning and data engineering projects in public. And the first project I am tackling in this series is Vigil: a real-time traffic accident detection system.
Thus, we will start the implementation of the system designed in the last post with a small POC that will:
Extract video frames from a single camera feed
Publish them to a ZeroMQ queue
Have a single consumer that will run inference on each frame and log out the result
In this post I’ll detail how I built the first part of this POC: the camera feed extractor.
Setting up the project
For this project I am going to try out uv, a python package and project manager written in Rust that claims being super fast, as well as solving some common headaches. This was built by Astral, the same guys that built ruff, the python linter. I’ve been through various package/project/env managers like pyenv, pip-tools and poetry, and had recently settled with a minimal pyenv+virtualenv+pip setup for my latest projects. But I am willing to give uv a try as its CLI seems pretty straight-forward. I’ll also use Python 3.11 as it is pretty mature by now and supported by many popular libraries.
Implementing the camera feed extractor
As mentioned in the intro, I’ll go through how I implemented the piece of code that takes a single camera feed, extracts each frame and gets them ready to publish them to the queue. There is also some extra work needed to detect if the video pulled from the feed url was already processed or is a new one. This has to do with the way these feeds are provided (see more here).
Managing state
I started by creating a dataclass to represent a camera feed. Dataclasses, introduced in 3.7, are a great utility to write classes that hold data avoiding that boilerplate pain. They automatically provide initialisation, comparing and printing logic out of the box, and all you need to do is write the @dataclass decorator before your class definition.

For now, I simply added a name, video_source to hold the mp4 video url, and the time the feed video was last updated.
Fetching the video and extracting the frames
The extracting logic lives in its own class that takes in a CameraFeed when initialised. In the future it may take a list of them.

For the frame extraction, my mind went immediately to opencv. Throughout all my past machine learning projects that involved computer vision, opencv has been a constant, providing a great API to do all sort of image and video manipulations with ease.
In order to save disk IO overhead, I went looking for a way of streaming the video content from the url into memory and perform the frame extraction directly. Sadly I could not find a way to capture a video in opencv-python directly from a stream of bytes. I did find some tricky ways of doing a similar operation using ffmpeg, but it looked way too complicated for the task at hand.
So I basically used the all too popular requests package in combination with the neat tempfile module to download the mp4 video file and store it as a temporary file.

The stream argument is crucial here. It basically tells requests to keep the connection open and download the data in chunks, rather than loading the entire content into memory at once. This is especially important for large files like videos.
Then, using an all-too-pythonic context manager I create a temporary file, iterate over the response data in chunks, and write it to said file. The delete=false option is simply to instruct tempfile that I will manually instruct when the file should be deleted.
We are now ready to extract the frames of the downloaded video file.
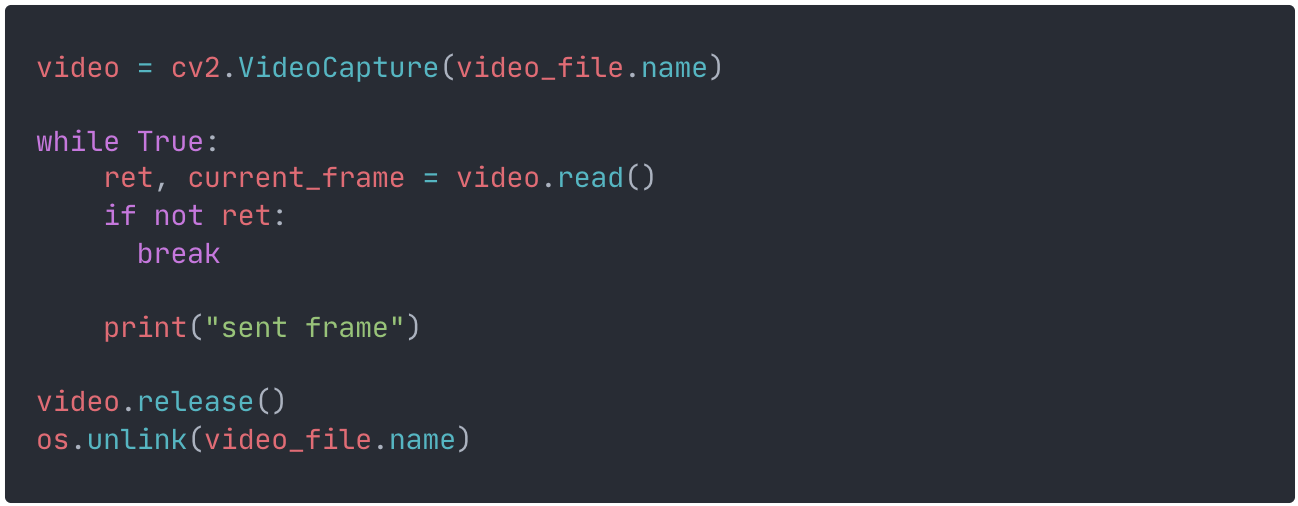
This is the run-of-the-mill way of extracting frames from videos with opencv used in all the machine learning projects I’ve ever come across. We load the video from file and use the read() method that returns a tuple containing the video frame (a 3d matrix of rgb pixel values) and a boolean flag representing if the frame was correctly read. When this flag is false, it usually means we’ve iterated through all of the frames. I know, we probably need to code in something to handle actual frame read errors, but this is a POC remember?
The print statement is where the queue publishing logic will be placed in the future. Finally, when all the frames have been sent, we release the opencv video object and instruct that the temporary file can now be deleted.
Avoid processing the same video twice
All I had left to do was some sort of deduping logic to avoid unnecessary processing, since each camera feed only refreshes its video every 5-10 minutes.
I started by implementing some ways of verifying if I was about to process the same video. First I stored and compared the mean of the pixel values of the video’s first frame. Then I simplified it by simply comparing a hash of the downloaded files. But after some rubber-ducking with a colleague at work (thanks
), he asked why I didn’t simply look at the Last-Modified header in the video’s HTTP request. This way I don’t even have to download the video file. The implementations was pretty straight-forward.
The only thing worth noting here is that we set the value to 0 when the header is not present. The integer casting is necessary due to the strange quirk in the datetime module where the timestamp() method is annotated with the float return type.
You can check out the full code here.
Testing all the things!
We finish up this post by having a quick look at the tests I wrote for this functionality.
I used the popular pytest package instead of the builtin unittest module, as it provides some very nice utilities around monkeypatching, mocking and state management. I decided to write two unit/component tests that cover the two main scenarios of the extractor. They are fetching a video and extracting its frames, and detect the video has already been process and exiting early.
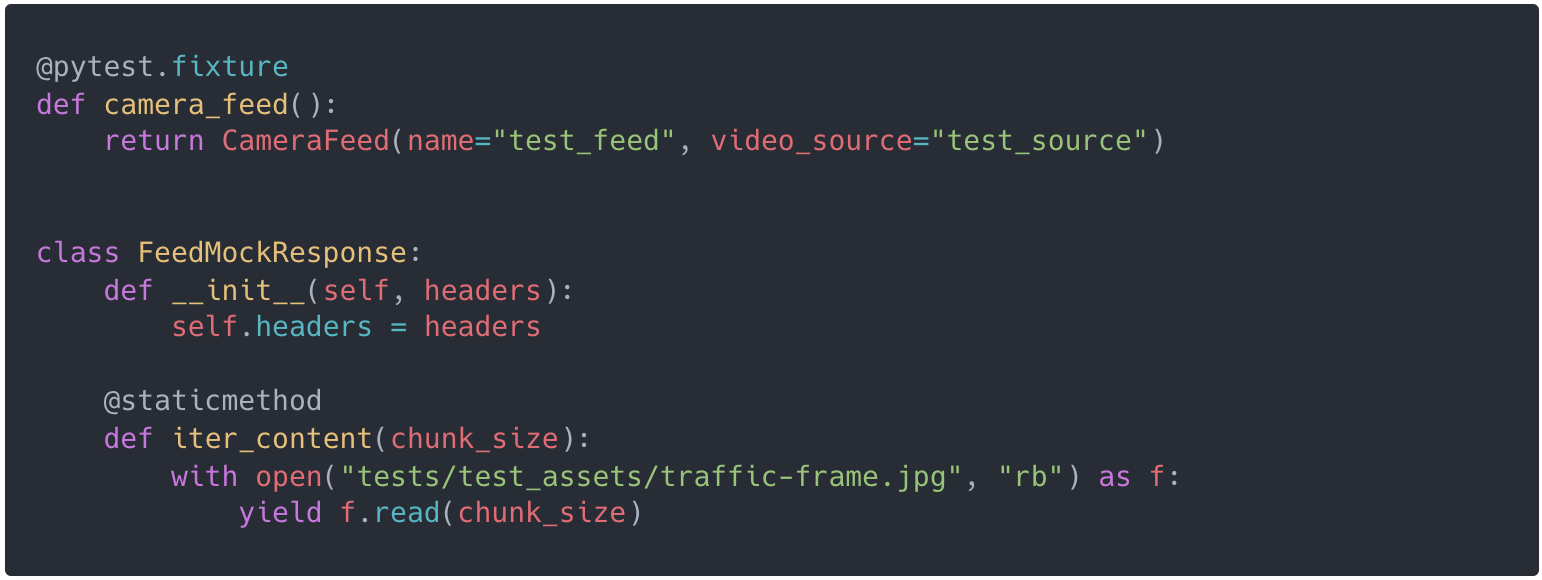
I started with some scaffolding: creating a test CameraFeed object to be reused in all tests, and a dynamic stub for requests module where I can specify the header context. This stub also returns a content iterator with a single test frame.


In the first test, we start by monkeypatching the .get() method of the requests module to return the previously defined stubs. Then we initialise our FeedExtractor and directly call the extracting function, asserting the value printed to stdout.
The second test is a variation of the first where we call _extract_frames() twice, expecting that the first call sets the last_updated value correctly, exits early and prints out the appropriate message.
One final test
Before wrapping up I also wanted to perform a manual test with a real video url, and see if everything works as expected. So I hardcoded the following:

And ran it with great success!

Again, you can check out the whole project on Github.
Next time on Vigil….
In the next post we’ll dive deeper on the details of each frame, how to publish it to our queue in an efficient manner, and consume it with our frame classifier. Stay tuned!