



Vigil #3 - Zero to One
Getting our first accident detections

We finished our previous post with a fully functioning (and tested) camera feed frame extractor. As you might recall, I started this project with the milestone of building a POC to cover much of the end-to-end data flow, but for only a single camera feed. The goal of this milestone was to focus on the “0 to 1” work, and leaving the “1 to n” challenges as iterative improvements based on observations.
We now have a service that periodically fetches camera feed videos, extracts frames, and does some extra stuff like preventing from processing the same video twice. We now need to send these frames down the wire to another service that will run a computer vision model and detect if there are any accidents in the frames.
ZeroMQ
The main reason to separate the frame extractor and classifier is the fact that extracting and classifying frames have different resource and computational demands Frame extraction primarily involves I/O operations and video processing, while classification requires more compute for neural network inference.
A message queue provides a way to distribute the classifying load through several workers that can work in parallel and scale independently of the extractors. As mentioned previously, the nature of this system does not require strict consistency or persistence guarantees. We can afford losing a few frames without compromising the classifying and alerting mechanism. That is why I considered ZeroMQ (ZMQ) when designing the system.
In my head ZeroMQ was simply a queue based messaging system that was stripped down and without a broker. But I stumbled upon the amazing ZeroMQ Guide, and got sucked in. I quickly learned that ZMQ is so much more than a simple abstraction over TCP sockets. It basically provides the building blocks for building distributed systems. It supports many sync and async messaging patterns (like Request-Reply, PubSub, Push-Pull, etc) as well as routing capabilities and even out-of-the-box niceties like handling disconnections and reconnections. And it does all this while maintaining a “culture of minimalism” that “adds power by removing complexity rather than by exposing new functionality.”
Changes in the Frame Extractor
For this POC though, since I only have a single extractor and a single classifier, I used a simple push-pull messaging pattern. When I get to the “1 to n” scenarios I’ll explore the different possibilites ZeroMQ gives us.
I started by modifying the FeedExtractor class to incorporate the socket initialisation and tear down logic.

I also added some logic to catch SIGINT signals and ensure that socket termination was done properly.

Finally, I made some changes to the frame extracting function. The first and most obvious one was to send the frame to the ZMQ queue. ZeroMQ allows for various data formats in its messages, such as serialised binary data, strings or raw stream data. For the moment I chose to serialise an object containing the feed name, timestamp and frame (as numpy array) with the popular pickle package.
I also added a frame skip parameter to prevent sending every single frame. Each video has around 200 to 300 frames, which is an order of magnitude more than what is needed to provide timely information.

Frame Classification
I was now ready to build the frame classification service. My future vision is to be able to spawn a number of instances of this services as parallel workers that utilize the GPU parallelism capabilities to classify the multiple frames arriving at the queue from multiple feeds.
Computer Vision Model
For this POC I wanted to use something out of the box. I considered using an API based classification service, but this didn’t align with the project learning goals of orchestrating a distributed set of workers running inference from a GPU. This calls for having a model running locally, and thus I started looking for pre-trained models for accident classification.
I started looking in the usual places, HuggingFace and Github, but while searching I found Roboflow. Roboflow is platform somewhat similar to HuggingFace but focused on computer vision and with a wider feature set on training and deployment. Looking through their repository of datasets and models I quickly found a model that does object detection for vehicles and classification of accidents. They provide an option to either run inference through their API, or download the model and run it locally. For the latter option they allow unlimited downloads of the model for 5 different devices per month on the free tier. That is more than enough for now, though the learning goals of this project include training/fine-tuning my own model with freely available datasets.
The Classifier Service
The initialisation of the classifier starts with the setup of the ZMQ socket and the download of the deep learning model using the Roboflow Python SDK. I used a small helper library to load the variables in my .env file (such as API keys) as environment variables. This .env is of course git ignored, so don’t get any ideas 😀.
Immediately after initialisation, the service starts listening for messages in the ZMQ socket.

The thing left to do was to implement the process_messsage function. I starter by deserialising, extracting the data in the message, and running inference on the frame. Since we are dealing with an object detection model, its output is an array of bounding boxes corresponding with each detect object, along with the inferred class and confidence score. For now I only want to ascertain if there is at least a detected object classified as accident with a minimum predefined confidence score. Using the any operator and a simple list comprehension I can achieve just that.
If I find an accident I simply log it for now, and save the corresponding image and detection data for later analysis.

Taking it for a test drive
It was now time fire these services up and taking them for a spin.


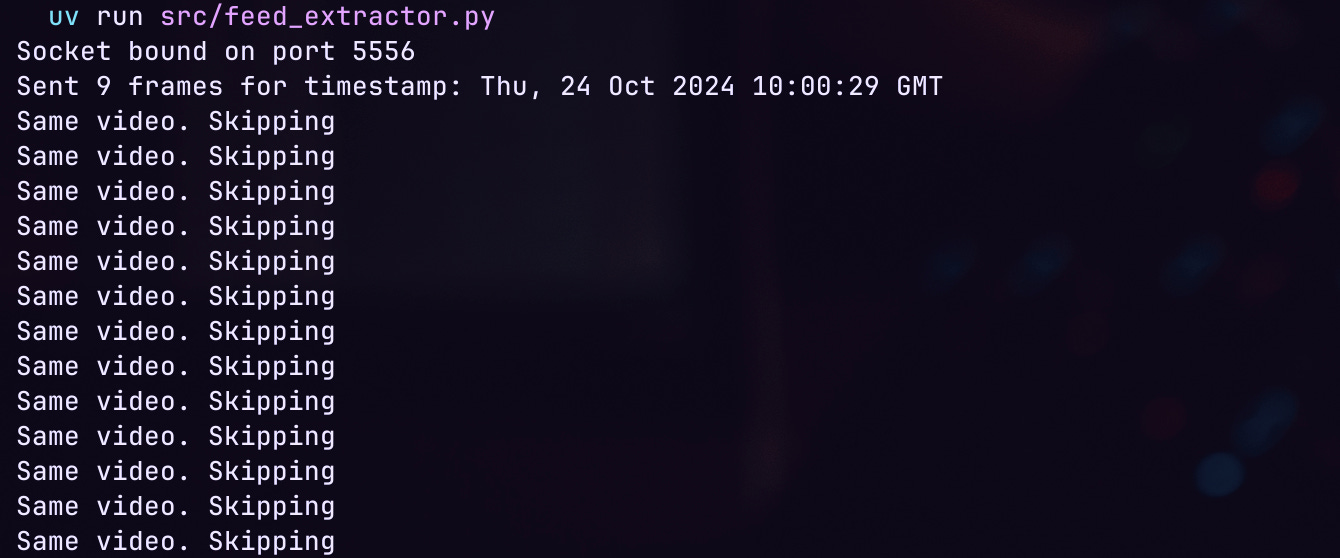
And boom! We are successfully extracting frames and sending them through the ZeroMQ socket. On the other side, we are successfully receiving the frames and running classification. The repeated video skip and the frame skip seem to also be working. But we need to do some unit tests to confirm.
In some later runs I found that the classifier incorrectly classified some frames positively when there were no accidents, even with a minimum confidence score of 70%.
Next time on Vigil
Now comes the fun part, the 1 to n. And a few things immediately pop into my mind:
Fetch the country-wide list of camera feeds and test if a single instance of the extractor can handle the load.
Find a way to parallelise multiple instances of the classification workers on the same GPU
Adapt the ZeroMQ queue to distribute the frames to the classification workers in a fair and efficient manner
As always you can check all the code at Github. See you next time. 👋