



Vigil #4 - A detour through video processing lands
Upgrading my frame extraction method

In the last post, we achieved an end-to-end working prototype. It pulls frames from a single camera feed and sends them through a ZMQ queue to a classifier worker. This worker performs inference using a computer vision model to detect any accidents in the frames.
Now, it's time to scale up to handle a larger number of camera feeds.
Country wide reach
As you may recall from the first post in this series, I discovered that the Portuguese road and transport authority has a traffic camera website. This website provides an API that I can leverage to gather information about all available cameras and their respective feeds..
Fetching all the feeds data
The purpose of creating the CameraFeed dataclass was not only to represent state but also to abstract the specific details of diverse future data sources. This allows us to create a kind of interface that all data sources can use to plug into the system.
In line with this, I created a separate class to handle the specific details of the Portuguese authority API and provide a method to fetch all camera feeds and their metadata.
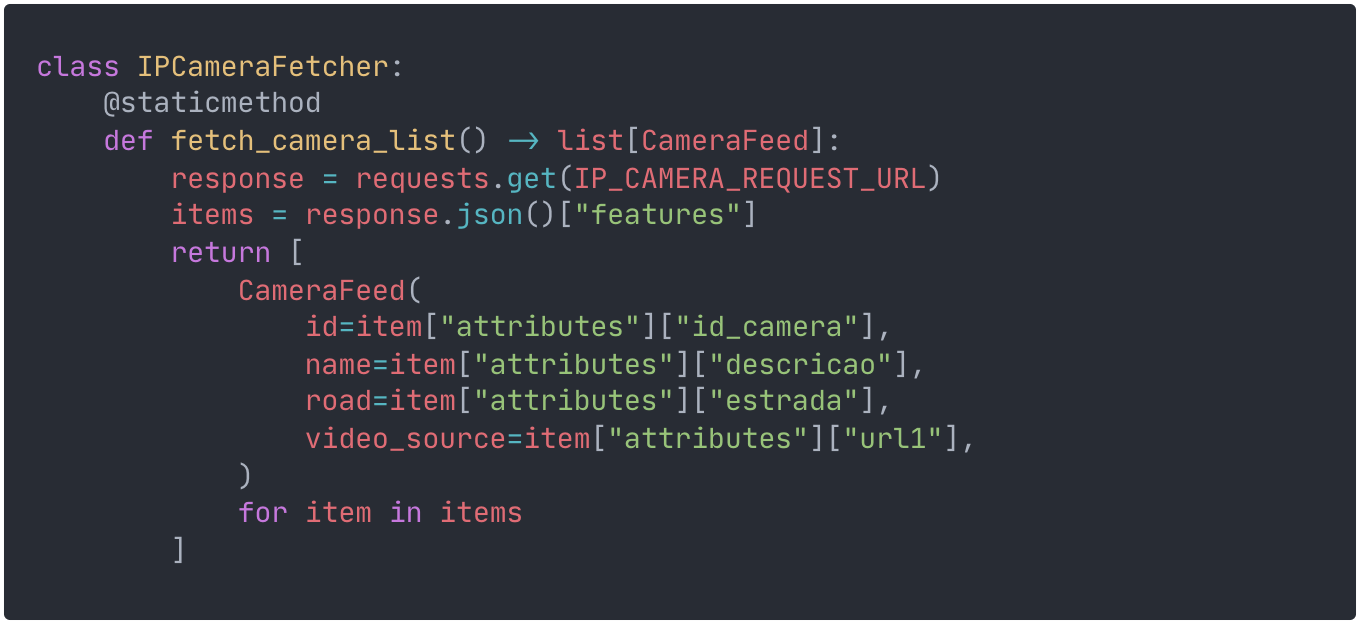
This simple class has a static method that parses the JSON response containing all available cameras into a list of CameraFeed objects, serving as our data source interface.
Opening the floodgates
It was time to test our system and have it extract and classify frames from all available cameras instead of just a single one. The first step was to modify the FeedExtractor class to process a list of feeds instead of a single feed.

The modification was straightforward: extract frames from each feed sequentially. I also added code to measure the time it took to iterate through the entire list of feeds, extract frames, and send them. I used time.perf_counter() for this, as it's specifically designed for benchmarking short-duration code execution with consistent and monotonic measurements.
The first test
As you can see, the frame extractor is a bit clunky. It takes more than one second per camera feed, totaling 231 seconds to complete one pass through all 180 available cameras. Furthermore, we are getting errors when reading downloaded video files, which makes me question the overall OpenCV approach.
The frame classifier, on the other hand, appears to be handling the load effectively. We can clearly see it processing each batch of frames that comes through the queue.
A fork in the road
I now faced a decision. On the one hand, the feed extractor wasn't performant enough and couldn't extract frames from a reasonable number of cameras in a timely manner. There was clear room for improvement by parallelizing the extraction process, as network I/O seemed to be the most obvious bottleneck. On the other hand, the errors fetching and processing videos were increasing as I increased the number of feeds being processed.
I chose to address the video processing issue first, prioritizing a well-functioning system over a performant one.
Bringing on ffmpeg
As you may recall, our approach was to download the MP4 video file, store it as a temporary file, and then read it with OpenCV to extract its frames. I briefly considered streaming the video content directly from the URL into memory and performing frame extraction there. This would save disk I/O overhead and simplify the whole process by reducing the number of moving parts and potential points of failure. Upon glancing at the FFmpeg documentation, it seemed cumbersome, and I went with the easier OpenCV alternative. It was now time to revisit FFmpeg.
Probing for metadata

began by using probe() to fetch the streams' headers, allowing me to get video metadata without downloading the video content. You'll notice that I iterate through probe["streams"]. This is a list of all streams in the video file (video, audio, subtitles, etc.), and here, I'm only interested in the video stream.
I then obtained the video dimensions, duration, and calculated the total number of frames I would extract based on the desired frames-per-second ratio. For example, with FPS_TO_EXTRACT set to 1, we will extract one frame per second of video.
FFmpeg Pipeline Setup
FFmpeg operates using a pipeline-based architecture that processes media data in sequential stages.
A pipeline processes data in this sequence:
Input data chunks flow from sources.
Data passes through transformation components (decoders, filters, encoders, etc.).
Transformed data moves towards output sinks.

Our pipeline begins by reading the input from the video URL and applying an FPS filter to reduce the number of extracted frames. It then defines the output sink as a pipe that we can later use to create NumPy arrays. Specifying the pixel format was crucial to ensure that the array had the typical RGB image matrix format used in deep learning pipelines.
Frame Processing Loop

My next step was to run the pipeline in a loop until no more bytes were output. I began by reading the data piped through stdout, considering the total number of pixels, each with a value for red, blue, and green (RGB). I then took those raw bytes and used NumPy's ability to create an array from raw bytes, represented as integers in the usual RGB image matrix shape.
Finally, it was simply a matter of serializing the camera feed metadata along with the created frame and sending it through ZMQ.
The result
Great success! We are now extracting frames with no errors whatsoever. The network I/O bottleneck is still present, but a run through all the cameras now takes around 210 seconds, reflecting a small performance increase in processing the videos.
Next time on Vigil
After this small detour, we will return to the mission of distributing workload and network calls to hopefully extract and classify frames much faster, without having to wait around 200 seconds for each pass through the cameras.
As always you can check all the code at Github. See you next time. 👋